Решил разбить свой технический блог на русскоязычный и англоязычный - все таки двуязычные записи смотрятся весьма .. странно. Буду по возможности дублировать записи там и там. :)
суббота, 15 декабря 2012 г.
воскресенье, 16 сентября 2012 г.
Конец споров MySQL vs PostgreSQL
English is here
Хорошая статья по поводу вечного "срача" MySQL vs PostgreSQL, но на английском. Много букв, но кому лень читать - вот вывод, в моем кривом переводе -
"MySQL разработана с мыслью, что приложения обеспечивают логику, а база данных обеспечивает "тупое" хранение состояния приложения. Хотя это немного изменилось с добавлением определяемых пользователем функций и хранимых процедур, общий дизайн ограничивает MySQL подобным паттерном использования. Это не обязательно плохо, поскольку, традиционно, из за затрат на лицензирование программного обеспечение и требований приложения часто требуется, чтобы даже передовые системы баз данных, такие как Oracle использовались таким образом. MySQL нацелена на мир "мое приложение, моя база данных" и, как правило, для этого достаточно, особенно, когда наименьший общий знаменатель используется для обеспечения портабельности.
PostgreSQL, с другой стороны, разработана с мыслью, что база данных сама по себе является инструментом моделирования, а также о том, что приложения взаимодействуют с ним по API определенным в SQL. Адвокаты объектно-реляционной модели отмечают, что часто для того чтобы получить приемлемую производительность в сложных ситуациях требуется перенести некоторую логику в базу данных и даже привязать ее к структурам данных в БД. В этой модели, база данных сама по себе является частью платформы, которая предоставляет API, и несколько приложений могут считывать или записывать данные с помощью этих API. Таким образом, БД лучше всего рассматривать как решение для продвинутого моделирования и централизованного хранения данных, а не как простой бекенд для приложения.
Эти различия показывают, что, когда пользователи PostgreSQL жалуются, что MySQL не является "реальной системой управления базами данных" и пользователи MySQL оспаривают это, говоря что это на самом деле разница в определениях, и в этом случае определения обманчиво далеки друг от друга. Понимание этих различий, я думаю, играет ключевую роль в обеспечении осознанного выбора."
Хорошая статья по поводу вечного "срача" MySQL vs PostgreSQL, но на английском. Много букв, но кому лень читать - вот вывод, в моем кривом переводе -
"MySQL разработана с мыслью, что приложения обеспечивают логику, а база данных обеспечивает "тупое" хранение состояния приложения. Хотя это немного изменилось с добавлением определяемых пользователем функций и хранимых процедур, общий дизайн ограничивает MySQL подобным паттерном использования. Это не обязательно плохо, поскольку, традиционно, из за затрат на лицензирование программного обеспечение и требований приложения часто требуется, чтобы даже передовые системы баз данных, такие как Oracle использовались таким образом. MySQL нацелена на мир "мое приложение, моя база данных" и, как правило, для этого достаточно, особенно, когда наименьший общий знаменатель используется для обеспечения портабельности.
PostgreSQL, с другой стороны, разработана с мыслью, что база данных сама по себе является инструментом моделирования, а также о том, что приложения взаимодействуют с ним по API определенным в SQL. Адвокаты объектно-реляционной модели отмечают, что часто для того чтобы получить приемлемую производительность в сложных ситуациях требуется перенести некоторую логику в базу данных и даже привязать ее к структурам данных в БД. В этой модели, база данных сама по себе является частью платформы, которая предоставляет API, и несколько приложений могут считывать или записывать данные с помощью этих API. Таким образом, БД лучше всего рассматривать как решение для продвинутого моделирования и централизованного хранения данных, а не как простой бекенд для приложения.
Эти различия показывают, что, когда пользователи PostgreSQL жалуются, что MySQL не является "реальной системой управления базами данных" и пользователи MySQL оспаривают это, говоря что это на самом деле разница в определениях, и в этом случае определения обманчиво далеки друг от друга. Понимание этих различий, я думаю, играет ключевую роль в обеспечении осознанного выбора."
пятница, 20 июля 2012 г.
Еще прекрасное
Пара ссылок.
https://www.shortcutfoo.com - тренируйте шорткаты для вашего любимого текстового редактора!
https://github.com/jkbr/httpie - типа, cURL для людей - может парсить JSON и красиво раскрашивать результат.
https://www.shortcutfoo.com - тренируйте шорткаты для вашего любимого текстового редактора!
https://github.com/jkbr/httpie - типа, cURL для людей - может парсить JSON и красиво раскрашивать результат.

воскресенье, 8 июля 2012 г.
Грустная новость, камрады
English text is here.
Грустная новость, камрады.
На Хабре пробегала статья про высокие нагрузки на порносайтах, в которой кто то упомянул презентацию от YouPorn про их архитектуру. Тут и я припомнил, что недавно как раз были новости что YouPorn перешел на Redis и достиг там какой то сумасшедшей производительности - 300K/сек. Ну и YouPorn был раньше славен тем, что был написан на Perl, что всячески упоминалось в разных холиварах, безотносительно порно - как никак сайт из Alexa Top-100 на Perl - это же круто!
Так вот - больше нет.
Открываем вышеупомянутую презентацию (вот ссылка на GoogleDocs / оригинал), читаем -
 В остальном кстати, архитектура у них довольно стандартна - HaProxy + Varnish + Nginx/PHP-FPM/Symfony2 + Redis/MySQL, для логирования используется Syslog-ng, единственно что удивляет - это использование ActiveMQ для записи в БД/Redis - хотя если я правильно понял, им они как раз не очень довольны.
В остальном кстати, архитектура у них довольно стандартна - HaProxy + Varnish + Nginx/PHP-FPM/Symfony2 + Redis/MySQL, для логирования используется Syslog-ng, единственно что удивляет - это использование ActiveMQ для записи в БД/Redis - хотя если я правильно понял, им они как раз не очень довольны.
Грустная новость, камрады.
На Хабре пробегала статья про высокие нагрузки на порносайтах, в которой кто то упомянул презентацию от YouPorn про их архитектуру. Тут и я припомнил, что недавно как раз были новости что YouPorn перешел на Redis и достиг там какой то сумасшедшей производительности - 300K/сек. Ну и YouPorn был раньше славен тем, что был написан на Perl, что всячески упоминалось в разных холиварах, безотносительно порно - как никак сайт из Alexa Top-100 на Perl - это же круто!
Так вот - больше нет.
Открываем вышеупомянутую презентацию (вот ссылка на GoogleDocs / оригинал), читаем -
- Written in PERL with a very complex architecture
- First few months dedicated to learning the site, maintain it, and plan the re-write.
- Re-write started in August 2011 and was originally planned for a delivery in mid-November.
- Actually launched at the end of January.

понедельник, 25 июня 2012 г.
А вы знаете про perlsecret?
English test is here
Читаю perlsecret. Оказалось забавная штука, всем советую. Ообенно понравился оператор "~~<>", называемый kite (воздушный змей) или ... sperm (тут и без перевода думаю понятно).
Приведу выдержку из документации полностью -
"Discovered by Philippe Bruhat, 2012. (Alternate nickname: "sperm")
This operator is actually a combination of the inchworm and the diamond operator. It provides scalar context to the
It's only useful in list context (since <> already returns a single line of input in scalar and void contexts), for example for getting several lines at once:
Mnemonic: It provides a feature that is tied to one line, a string, as it were. (Tye McQueen in http://www.perlmonks.org/?node_id=959906)."
Читаю perlsecret. Оказалось забавная штука, всем советую. Ообенно понравился оператор "~~<>", называемый kite (воздушный змей) или ... sperm (тут и без перевода думаю понятно).
Приведу выдержку из документации полностью -
"Discovered by Philippe Bruhat, 2012. (Alternate nickname: "sperm")
This operator is actually a combination of the inchworm and the diamond operator. It provides scalar context to the
readline() builtin, thus returning a single line of input.It's only useful in list context (since <> already returns a single line of input in scalar and void contexts), for example for getting several lines at once:
@triplets = ( ~~<>, ~~<>, ~~<> ); # three sperms in a single egg?Like the other operators based on bracketing constructs, the kite is a container, and can carry a payload (a file handle, in this case).
Mnemonic: It provides a feature that is tied to one line, a string, as it were. (Tye McQueen in http://www.perlmonks.org/?node_id=959906)."
воскресенье, 24 июня 2012 г.
Spacewar!, Computer Space, Pong...
Читаю книгу по истории видео игр, вот эту -
 Книга 2001 года, но очень хорошая. На русский насколько мне известно, к сожалению, не переводилась. Сначала описывается история механических игр - в основном типа "пинболл", потом рассказывается про создание первой компьютерной игры для PDP-1 под названием Spacewars!, потом история первой TV приставки Magnavox Odyssey, ну и конечно история Atari .
Книга 2001 года, но очень хорошая. На русский насколько мне известно, к сожалению, не переводилась. Сначала описывается история механических игр - в основном типа "пинболл", потом рассказывается про создание первой компьютерной игры для PDP-1 под названием Spacewars!, потом история первой TV приставки Magnavox Odyssey, ну и конечно история Atari .
Интересно, что первой игрой Atari должен быть клон Spacewars! под названием Computer Space, но неожиданно хитом стала простая игра Pong, которуюнаписал спроектировал и собрал (на дискретной логике, никаких CPU!) талантливый инженер Al Allcorn. Причем что забавно, директор Atari Nolal Bushnell дал задание Allcornу только чтобы чем то его занять, а сам проектировал Computer Space, думая что именно она станет хитом. :)
Естественно, мне стало интересно как выглядели эти игры и каково в них было играть. В нашем то детстве ничего кроме Морского боя и "Ну, погоди!" ничего и не было, да и в 60-70 многие из нас даже еще не родились. Начал рыть Интернет в поисках эмуляторов...
Со Spacewars! все оказалось просто - есть все работает на эмуляторе PDP-1 прямо в окне браузера -
 Первая ракета управляется клавишами "a", "s", "d", "f", вторая - "k", "l", ";", "'". Архаичная, но забавная игрушка - это был на минутку 1962 год, правда PDP-1 на тот момент стоила порядка $100.000 - позволить ее себе могли только универитеты.
Первая ракета управляется клавишами "a", "s", "d", "f", вторая - "k", "l", ";", "'". Архаичная, но забавная игрушка - это был на минутку 1962 год, правда PDP-1 на тот момент стоила порядка $100.000 - позволить ее себе могли только универитеты.
С Computer Space все оказалось хуже - так как CPU там нет, нормальных эмуляторов тоже не имеется, только клоны, разной степени схожести. Вот вроде самый удачный -



Интересно, что первой игрой Atari должен быть клон Spacewars! под названием Computer Space, но неожиданно хитом стала простая игра Pong, которую
Естественно, мне стало интересно как выглядели эти игры и каково в них было играть. В нашем то детстве ничего кроме Морского боя и "Ну, погоди!" ничего и не было, да и в 60-70 многие из нас даже еще не родились. Начал рыть Интернет в поисках эмуляторов...
Со Spacewars! все оказалось просто - есть все работает на эмуляторе PDP-1 прямо в окне браузера -
С Computer Space все оказалось хуже - так как CPU там нет, нормальных эмуляторов тоже не имеется, только клоны, разной степени схожести. Вот вроде самый удачный -
Ну и Pong.

Несмотря на то что по Pong информации в Сети очень много - например на http://www.pong-story.com, нормальных эмуляторов также нет и не предвидится. Есть несколько проектов по эмуляции логических интегральных схем - DICE, DiscreteSIM, но на современном железе скорость составляет от пары кадров в секунду, до нескольких кадров в минуту (!).
Поэтому приходится довольствоваться разной степени точности клонами, многие из которых эмулируют не изначальный аркадный дизайн, а последующую систему-на-чипе AY-3-8500 или домашнюю TV версию.
Ну а для любителей современноcти можно порекомендовать более cовременную реинкарнацию 2007 года - Plasma Pong. Суть игры та же, но все действо происходит на фоне красивых плазма-эффектов в стиле демосцены.

Сама игра выпилена с официального сайта из за нарушения копирайта Atari, но ее можно скачать например на AG.ru
понедельник, 18 июня 2012 г.
воскресенье, 10 июня 2012 г.
Очередной раз про взлом паролей
English text is here
Я давно интересуюсь темами IT-безопасности, криптографией и (связанной с ними обеими) парольной безопасностью, даже делал на эту тему блиц-доклад на PerlMova еще в 2010 г. Тем более любопытно, что произошло в этой области в последнее время. А произошло немало - сначала утечка паролей LinkedIn, потом Lastfm / Eharmony. В обоих случаях использовались несоленые хеши (извините, но єто вообще то капец) - sha1 в случае LinkedIn и md5 в случае Lastfm (самих хешей в случае с Lastfm правда предоставлено не было, на факт что за год было вскрыто 95% всех паролей говорит сам за себя).
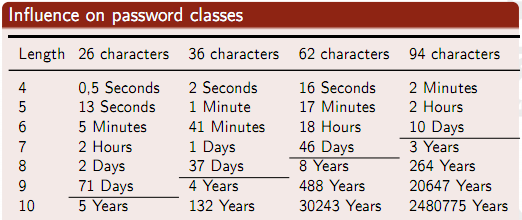
После всей этой катавасии широко известный в укзих кругах Poul-Henning Kamp, объявил, что созданную им в 1995 году реализацию системы хэширования паролей md5crypt больше нельзя считать безопасной, так как современные брутфорсеры паролей могут перебирать более 1 млрд. MD5 хешей в секунду (порядка 1 млн. md5crypt/сек), что слишком много - простые пароли могут быть быстро взломаны. Желающие могут ознакомиться с занятной презентацией Speeding up GPU-based password cracking, откуда мне понравилась следующая табличка -
 То есть 8ми символьные буквенноцифровые пароли уже ненадежны - 2 дня на полный брутфорс - это просто катастрофа с точки зрения безопасности. (кстати, в 2010 году в моем докладе у меня получилось вообще 20 минут - правда брутер был мощнее 2.7 млрд. хешей в секунду, так что возможно в докладе идет речь как раз о md5crypt).
То есть 8ми символьные буквенноцифровые пароли уже ненадежны - 2 дня на полный брутфорс - это просто катастрофа с точки зрения безопасности. (кстати, в 2010 году в моем докладе у меня получилось вообще 20 минут - правда брутер был мощнее 2.7 млрд. хешей в секунду, так что возможно в докладе идет речь как раз о md5crypt).
Выход собственно всем уже ясен и понятен - использовать для хранения хешей паролей то, что было придумано для хранения хешей паролей - а именно - bcrypt, scrypt или PBKDF2.
Тут еще можно добавить очень хороший доклад с PHDays по теме хранения паролей от тоже весьма известного в кругах безопасников Александра Песляка aka Solar Designer - только перемотайте на 14:00:00 (слайды к докладу).
Я давно интересуюсь темами IT-безопасности, криптографией и (связанной с ними обеими) парольной безопасностью, даже делал на эту тему блиц-доклад на PerlMova еще в 2010 г. Тем более любопытно, что произошло в этой области в последнее время. А произошло немало - сначала утечка паролей LinkedIn, потом Lastfm / Eharmony. В обоих случаях использовались несоленые хеши (извините, но єто вообще то капец) - sha1 в случае LinkedIn и md5 в случае Lastfm (самих хешей в случае с Lastfm правда предоставлено не было, на факт что за год было вскрыто 95% всех паролей говорит сам за себя).
После всей этой катавасии широко известный в укзих кругах Poul-Henning Kamp, объявил, что созданную им в 1995 году реализацию системы хэширования паролей md5crypt больше нельзя считать безопасной, так как современные брутфорсеры паролей могут перебирать более 1 млрд. MD5 хешей в секунду (порядка 1 млн. md5crypt/сек), что слишком много - простые пароли могут быть быстро взломаны. Желающие могут ознакомиться с занятной презентацией Speeding up GPU-based password cracking, откуда мне понравилась следующая табличка -
Выход собственно всем уже ясен и понятен - использовать для хранения хешей паролей то, что было придумано для хранения хешей паролей - а именно - bcrypt, scrypt или PBKDF2.
Тут еще можно добавить очень хороший доклад с PHDays по теме хранения паролей от тоже весьма известного в кругах безопасников Александра Песляка aka Solar Designer - только перемотайте на 14:00:00 (слайды к докладу).
понедельник, 9 апреля 2012 г.
Несколько интересных тулзов
English text is here
Парочка интересных вещей - на будущее, на посмотреть - пусть ссылки побудут тут.
1. Logstash - http://logstash.net/ - Могучий обработчик логов. Принимает логи из кучи источников , применяет к ним кучу фильтров и складывает куда надо. "Куда надо" может быть ElasticSearch-кластер, ко всему этому делу есть вебинтерфейс и куча плагинов (для amqp, greylog2, graphite, etc). Похож на Splunk, может не такой крутой, но бесплатный (Цена на Splunk - та еще жесть). Клиент написан на JRuby. :)
2. Книжка по Varnish - "От создателей", как говорится. Скоро обещают PDF и epub форматы.
Парочка интересных вещей - на будущее, на посмотреть - пусть ссылки побудут тут.
1. Logstash - http://logstash.net/ - Могучий обработчик логов. Принимает логи из кучи источников , применяет к ним кучу фильтров и складывает куда надо. "Куда надо" может быть ElasticSearch-кластер, ко всему этому делу есть вебинтерфейс и куча плагинов (для amqp, greylog2, graphite, etc). Похож на Splunk, может не такой крутой, но бесплатный (Цена на Splunk - та еще жесть). Клиент написан на JRuby. :)
2. Книжка по Varnish - "От создателей", как говорится. Скоро обещают PDF и epub форматы.
пятница, 16 марта 2012 г.
Почему сервер тормозит?
English text is here, as usual. :)
Супер.
Очень интересные ссылки обнаружил в блоге разработчиков DTrace -
1. The USE Method - http://dtrace.org/blogs/brendan/2012/02/29/the-use-method/
2. The USE Method: Solaris checklist - http://dtrace.org/blogs/brendan/2012/03/01/the-use-method-solaris-performance-checklist/
3. The USE Method: Linux checklist - http://dtrace.org/blogs/brendan/2012/03/07/the-use-method-linux-performance-checklist/
Вкратце - изложена очень простая, но эффективная методика определения проблем с производительностью сервера - USE (utilization, saturation, errors) метод. То есть для каждого ресурса сервера - CPU, память, диски, сеть и т.д. мы проверяем
Как правило сначала нужно проверить ошибки, потом утилизацию - а потом уже очереди - хотя и не всегда.
Это очень кратко - всем рекомендую ознакомиться со статьями. Во 2й и 3й части даются конкретные списки команд и рекомендации для проверки Солярки и Линукса по вышеописаному методу.
И кстати, метод волне юзабелен даже и без dtrace - тем более что под Линуксом его и нет, а имеющиеся реализации авторы блога терпеть не могут. :)
Супер.
Очень интересные ссылки обнаружил в блоге разработчиков DTrace -
1. The USE Method - http://dtrace.org/blogs/brendan/2012/02/29/the-use-method/
2. The USE Method: Solaris checklist - http://dtrace.org/blogs/brendan/2012/03/01/the-use-method-solaris-performance-checklist/
3. The USE Method: Linux checklist - http://dtrace.org/blogs/brendan/2012/03/07/the-use-method-linux-performance-checklist/
Вкратце - изложена очень простая, но эффективная методика определения проблем с производительностью сервера - USE (utilization, saturation, errors) метод. То есть для каждого ресурса сервера - CPU, память, диски, сеть и т.д. мы проверяем
- на сколько загружен ресурс от максимума (utlization)
- как часто ресурс не может обработать все запросы и ставит их в очередь (saturation)
- сколько ошибок генерируется при работе с данным ресурсом (errors).
Как правило сначала нужно проверить ошибки, потом утилизацию - а потом уже очереди - хотя и не всегда.
Это очень кратко - всем рекомендую ознакомиться со статьями. Во 2й и 3й части даются конкретные списки команд и рекомендации для проверки Солярки и Линукса по вышеописаному методу.
И кстати, метод волне юзабелен даже и без dtrace - тем более что под Линуксом его и нет, а имеющиеся реализации авторы блога терпеть не могут. :)
воскресенье, 4 марта 2012 г.
Пара ссылок
Нашел пару интересных ссылок -
1. http://www.windley.com/archives/2012/03/asynchronous_http_requests_in_perl_using_anyevent.shtml - небольшое введение в асинхронное программирование на Perl с помощью AnyEvent.
2. Прикольное обьяснение алгоритма Диффи-Хельмана (про безопасный обмен ключами) - все интересно и понятно.
Perl теперь и на Heroku !
English post is here.
К своему удивлению недавно узнал что на облачном хостинге Heroku теперь можно пускать приложения на (почти) любой веб-платформе. Делается это с помощью технологии называемой buldpacks. По идее это сделано чтобы можно было "потюнить" платформу/окружение - использовать новую версию Node.js или Ruby или что нибудь в этом роде. Но народ быстро смекнул в чем дело и нашлепал билдпаков на любой вкус и цвет - для C/Erlang/PHP/Go/Scala/etc - ну и конечно для Perl, причем один из них сделал самвеликий и ужасный :) Miyagawa - heroku-buildpack-perl. Им я и воспользовался чтобы перетащить свой Plusfeed.pl на Heroku со Stackato (где уже кончился триал). Теперь он живет на http://perlfeed-pl.herokuapp.com - заодно я пофиксил один неприятный баг из-за которого у сообщения менялся id при добавлении комментария или +1 - соответсвенно оно всплывало в ленте. :(
Вкратце я опишу как это делается.
1. Пишем стандартный Makefile.PL для своего приложения (можно использовать формат Build.PL) - вот мой -
use strict;
use warnings;
use ExtUtils::MakeMaker;
WriteMakefile(
NAME => 'plusfeed.pl',
VERSION => '0.05',
AUTHOR => 'Denis Zhdanov',
EXE_FILES => ['app.psgi'],
PREREQ_PM => {
'Google::Plus' => '0.004',
'XML::RSS' => '1.49',
'XML::Atom::SimpleFeed' => '0.86',
'Plack::App::Path::Router' => '0',
'Plack::App::File' => '0',
'Plack::Builder' => '0',
'Path::Router' => '0.11',
'CHI' => '0.5',
'Starman' => '0.3',
},
test => {TESTS => 't/*.t'}
);
2. Добавляем свое приложение на сайт с помощью кастомного билдпака -
git init
git add .
git commit -m "Initial version"
heroku create --stack cedar --buildpack \ http://github.com/miyagawa/heroku-buildpack-perl.git
git push heroku master
К своему удивлению недавно узнал что на облачном хостинге Heroku теперь можно пускать приложения на (почти) любой веб-платформе. Делается это с помощью технологии называемой buldpacks. По идее это сделано чтобы можно было "потюнить" платформу/окружение - использовать новую версию Node.js или Ruby или что нибудь в этом роде. Но народ быстро смекнул в чем дело и нашлепал билдпаков на любой вкус и цвет - для C/Erlang/PHP/Go/Scala/etc - ну и конечно для Perl, причем один из них сделал сам
Вкратце я опишу как это делается.
1. Пишем стандартный Makefile.PL для своего приложения (можно использовать формат Build.PL) - вот мой -
use strict;
use warnings;
use ExtUtils::MakeMaker;
WriteMakefile(
NAME => 'plusfeed.pl',
VERSION => '0.05',
AUTHOR => 'Denis Zhdanov
EXE_FILES => ['app.psgi'],
PREREQ_PM => {
'Google::Plus' => '0.004',
'XML::RSS' => '1.49',
'XML::Atom::SimpleFeed' => '0.86',
'Plack::App::Path::Router' => '0',
'Plack::App::File' => '0',
'Plack::Builder' => '0',
'Path::Router' => '0.11',
'CHI' => '0.5',
'Starman' => '0.3',
},
test => {TESTS => 't/*.t'}
);
2. Добавляем свое приложение на сайт с помощью кастомного билдпака -
git init
git add .
git commit -m "Initial version"
heroku create
git push heroku master
Вся магия содержится в строке с buildpack. После этого видим что то хохожее -
-----> Heroku receiving push
-----> Fetching custom buildpack... done
-----> Perl/PSGI app detected
-----> Installing dependencies
-----> Installing Starman
Starman is up to date. (0.3000)
-----> Discovering process types
Procfile declares types -> (none)
Default types for Perl/PSGI -> web
-----> Compiled slug size is 6.8MB
-----> Launching... done, v7
http://plusfeed-pl.herokuapp.com deployed to Heroku
(было много строк со сборкой cpanm и всех зависимостей, но только в первый раз, при обновлении этого не требуется).
Все пользуемся приложением и радуемся. :)
понедельник, 6 февраля 2012 г.
Подводные камни Project Voldemort
English post is here
Используется в одном из наших проектов такая штучка как Project Voldemort. Если вкратце, то это весьма любопытная реализация key-value storage aka NoSQL database. То есть даешь ему ключик и значение, и оно быстро в памяти это хранит/отдает и на диске тоже сохраняет, для персистентности. Оно на Java написано, и вообще больше из Java мира, но обслуживать и тюнить его приходится конечно нам, OPS Team. :)
В общем, столкнулись мы с одной проблемкой при эксплуатации, а именно - при большом трафике на этот Вольдеморт его база начала пухнуть со страшной силой - буквально десятки гигабайт в час - хотя девелоперы уверяли что такого количества данных там быть не должно. Пришлось копаться.
В результате "копаний" выяснилось следующее - в качестве бэкенда этот Вольдеморт использует так называемую BDB JE - Berkeley DB Java Edition, и оказалось что это JE совсем не похожа на обычную Berkeley DB. Оказывается она write only - то есть, основана на том же принципе что и журнализируемые ФС - при любой операции - запись, обновление, удаление - данные ДОЗАПИСЫВАЮТСЯ в файлики на диске и сами по себе они НЕ УДАЛЯЮТСЯ. Специальный cleaner процесс потом ходит и чистит устаревшие данные - проверяет общую утилизацию файлов в БД, и если она меньше bdb.cleaner.minUtilization процентов (по дефолту - 50%) начинает проверять каждый файлик, и если в нем меньше bdb.cleaner.min.file.utilization процентов (5% по дефолту) файлик удаляется, и данные из него переносятся в новый файл.
Хорошо. Вроде бы надо поиграться этими параметрами. Но что то не похоже чтобы утилизация у нас была 50% - уж очень много данных на диске хранится. Проверяем -
# java -jar /usr/local/voldemort/lib/je-4.0.92.jar DbSpace -h /usr/local/voldemort/data/bdb -u
File Size (KB) % Used
-------- --------- ------
00000000 61439 78
00000001 61439 75
00000002 61439 73
00000003 61439 74
...
000013f6 61415 1
000013fd 61392 2
000013fe 61411 3
00001400 61432 2
00001401 61439 1
...
0000186e 61413 100
0000186f 61376 100
00001870 16875 95
TOTALS 112583251 7
Опа-па. Не работает значит чистка. Пытаемся увеличить количество потоков для чистки - играемся с bdb.cleaner.threads (по умолчанию 1) - без пользы. В результате гугления натыкаемся на тред в форуме посвященному BDB JE (как выяснилось, очень полезный форум, если вы в каком либо виде используете BDB JE - обязательно почитайте).
Тред (сорри, сейчас что то найти его не могу) ясно говорит о том, что на очистку может сильно влиять размер кеша BDB. То есть, если кеш маловат - чистка может даже не запускаться, так как при большом количестве ключей желательно чтобы все они влезали в кеш, иначе сильно падает производительность очистки. Желательный размер кеша можно прикинуть используя следующую команду -
# java -jar /usr/local/voldemort/lib/je-4.0.92.jar DbCacheSize -records 1000000 -key 100 -data 300
Inputs: records=1000000 keySize=100 dataSize=300 nodeMax=128 density=80% overhead=10%
Cache Size Btree Size Description
-------------- -------------- -----------
177,752,177 159,976,960 Minimum, internal nodes only 208,665,600 187,799,040 Maximum, internal nodes only 586,641,066 527,976,960 Minimum, internal nodes and leaf nodes
617,554,488 555,799,040 Maximum, internal nodes and leaf nodes
Btree levels: 3
(где key и data - средний размер ключа и данных, в байтах).
То есть, для наших данных, на каждый миллион записей нужно около 200 МБ кеша - а записей у нас был не один миллион. :(
Итого - после выставления адекватных кешей (bdb.cache.size), за сутки утилизация БД выросла с 7% до искомых 50%, соответсвенно размер БД упал В РАЗЫ.
Мораль - изучайте используемую технологию (даже если она используется не напрямую, а опосредовано. :) )
вторник, 24 января 2012 г.
I know Kung-Fu now :)
Задался я по работе интересным вопросом - а как собственно узнать какое приложение под Linux грузит диск? Для CPU есть top - а для диска?
Дебианщики скажут - iotop, но там нужно свеженькое ядро, а у нас CentOS 5 на 2.6.18 - и что ж нам делать?
Оказывается есть минимум три выхода.
1. Если ядро 2.6.1 и новее - а оно наверно так и есть, можно сказать
% sudo sysctl vm.block_dump=1
и после чего в /var/log/debug начинает валиться что то типа
2. dstat - http://dag.wieers.com/home-made/dstat/
Тоже не "мегамагия", но на CentOS работает, хотя по дефолту выводит просто ИМЯ самого прожорливого до диска процесса - если их несколько (java?) то остается догадываться какой это именно процесс. В принципе плагины для него написаны на Питоне, и можно покопаться, но есть способ еще лучше.
3. SystemTap - http://sourceware.org/systemtap/
О, а вот это уже интересная штучка - аналог DTrace (который под Линукс нельзя портировать из за лицензионных ограничений). Поддерживается кучей контор, в т.ч. RedHat и IBM.
Полностью работоспособен в RHEL/Centos начиная с 5 версии. Для CentOS правда нужно доставить kernel-debug RPMки вручную (если у вас нестандартное ядро - придется их собрать и установить, но вся инфа есть тут - http://sourceware.org/systemtap/wiki/SystemTapOnCentOS)
Безопасен для production систем, вроде как - паники не вызывает.
Устанавиваем, идем на http://sourceware.org/systemtap/wiki/ScriptsTools, качаем disktop.stp, запускаем -
(На самом деле если копнуть глубже то цифрам трафика верить нельзя, но порядок нагрузки ясен. Почему обьяснено тут - http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/ )
Тулза, похоже, очень перспективная, нужно будет поковырять и изучить.
Дебианщики скажут - iotop, но там нужно свеженькое ядро, а у нас CentOS 5 на 2.6.18 - и что ж нам делать?
Оказывается есть минимум три выхода.
1. Если ядро 2.6.1 и новее - а оно наверно так и есть, можно сказать
% sudo sysctl vm.block_dump=1
и после чего в /var/log/debug начинает валиться что то типа
May 27 10:00:20 kex kernel: tail(11548): dirtied inode 14093100 (ld.so.cache) on sda1
May 27 10:00:20 kex kernel: tail(11548): dirtied inode 15269995 (libm.so.6) on sda1
May 27 10:00:20 kex kernel: tail(11548): dirtied inode 15270399 (libm-2.3.2.so) on sda1
...
May 27 10:00:20 kex kernel: tail(11548): dirtied inode 18154515 (locale-archive) on sda1
May 27 10:00:21 kex kernel: pdflush(140): WRITE block 76808312 on sda1
..
Это конечто не Бог весть что, но с помощью могучей магии Перла или шелла это можно распарсить и просуммировать - % grep sda1 /var/log/debug | grep READ | cut -d: -f4 | sort | uniq -c | sort -rn | head
1056 find(11566)
247 mysqld(11855)
43 mysqld(11751)
26 mysqld(11790)
21 tar(11717)
16 mysqladmin(11748)
13 mysqld(11899)
13 grep(4560)
12 mysqld(11863)
6 mysqld(11760)
В общем, хоть что то, но есть способ лучше -2. dstat - http://dag.wieers.com/home-made/dstat/
Тоже не "мегамагия", но на CentOS работает, хотя по дефолту выводит просто ИМЯ самого прожорливого до диска процесса - если их несколько (java?) то остается догадываться какой это именно процесс. В принципе плагины для него написаны на Питоне, и можно покопаться, но есть способ еще лучше.
3. SystemTap - http://sourceware.org/systemtap/
О, а вот это уже интересная штучка - аналог DTrace (который под Линукс нельзя портировать из за лицензионных ограничений). Поддерживается кучей контор, в т.ч. RedHat и IBM.
Полностью работоспособен в RHEL/Centos начиная с 5 версии. Для CentOS правда нужно доставить kernel-debug RPMки вручную (если у вас нестандартное ядро - придется их собрать и установить, но вся инфа есть тут - http://sourceware.org/systemtap/wiki/SystemTapOnCentOS)
Безопасен для production систем, вроде как - паники не вызывает.
Устанавиваем, идем на http://sourceware.org/systemtap/wiki/ScriptsTools, качаем disktop.stp, запускаем -
[root@localhost src]# stap -v disktop.stp
Pass 1: parsed user script and 72 library script(s) using 21380virt/12988res/2280shr kb, in 300usr/220sys/712real ms.
Pass 2: analyzed script: 6 probe(s), 33 function(s), 7 embed(s), 21 global(s) using 122028virt/45148res/4200shr kb, in 2430usr/3790sys/16852real ms.
Pass 3: translated to C into "/tmp/stapFxPYtp/stap_5caa87e008b9d53ed275791ebd211ed4_27487.c" using 119868virt/45400res/5432shr kb, in 660usr/290sys/1328real ms.
Pass 4: compiled C into "stap_5caa87e008b9d53ed275791ebd211ed4_27487.ko" in 4630usr/3600sys/11755real ms.
Pass 5: starting run.
Tue Jan 24 15:41:06 2012 , Average: 2Kb/sec, Read: 13Kb, Write: 1Kb
UID PID PPID CMD DEVICE T BYTES
500 3629 3621 pam_timestamp_c dm-0 R 13824
501 2759 2757 java dm-0 W 690
501 2545 2542 java dm-0 W 552
Tue Jan 24 15:41:11 2012 , Average: 2Kb/sec, Read: 13Kb, Write: 1Kb
UID PID PPID CMD DEVICE T BYTES
0 2395 1 VBoxService dm-0 R 13824
501 2545 2542 java dm-0 W 690
501 2759 2757 java dm-0 W 671
Tue Jan 24 15:41:16 2012 , Average: 2Kb/sec, Read: 13Kb, Write: 1Kb
UID PID PPID CMD DEVICE T BYTES
500 3629 3621 pam_timestamp_c dm-0 R 13824
501 2759 2757 java dm-0 W 690
501 2545 2542 java dm-0 W 671
Tue Jan 24 15:41:21 2012 , Average: 5Kb/sec, Read: 27Kb, Write: 1Kb
UID PID PPID CMD DEVICE T BYTES
0 2395 1 VBoxService dm-0 R 13824
500 3629 3621 pam_timestamp_c dm-0 R 13824
501 2545 2542 java dm-0 W 690
501 2759 2757 java dm-0 W 671
Последняя колонка - трафик в байтах. Ура, радуемся и крутим фонарики.(На самом деле если копнуть глубже то цифрам трафика верить нельзя, но порядок нагрузки ясен. Почему обьяснено тут - http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/ )
Тулза, похоже, очень перспективная, нужно будет поковырять и изучить.
Подписаться на:
Сообщения (Atom)